AI Research Papers: Computer Vision, NLP, and Vision–Language Models (VLM)
Latest AI research papers with summaries of breakthroughs in Computer Vision, Natural Language Processing (NLP), and Vision–Language Models (VLM)






Latest AI Research Papers in Computer Vision, NLP, and VLM (2025)
Curated list of cutting-edge AI research papers, highlighting key breakthroughs in Computer Vision, Natural Language Processing (NLP), and Vision–Language Models (VLM)
Recent Research Papers & Summaries (2025)


DINOv3 is a self-supervised framework for Vision Transformers that learns strong visual features without labeled data. It delivers competitive results on image recognition and segmentation benchmarks, setting a new standard for efficient representation learning in computer vision.
StableAvatar is a generative model for creating realistic talking avatars with accurate facial expressions and lip synchronization. It improves the quality of avatar animation for video, gaming, and communication, advancing state-of-the-art methods in controllable facial generation.


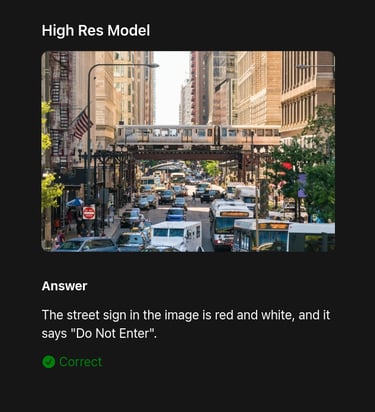
Qwen-Image is a large-scale vision–language model designed for multimodal understanding. By combining image recognition with text generation, it achieves strong results on benchmarks for captioning, retrieval, and reasoning, offering a powerful foundation for multimodal AI research.


InternVL3.5 is an open-source vision–language model that integrates large-scale visual and textual understanding. It shows strong performance in tasks such as captioning, cross-modal retrieval, and VQA, pushing forward multimodal reasoning in research and practical AI systems.


A powerful TTS model that generates up to 90 minutes of multi-speaker, expressive speech using an ultra-low frame-rate acoustic tokenizer and an LLM-driven diffusion decoder—designed for long-form audio like podcasts and audiobooks, with built-in disclaimers and watermarking for ethical use.