FastVLM: Efficient Vision Encoding for Vision Language Models (2025)
Summary of the FastVLM research paper: an efficient hybrid visual encoder that dramatically reduces latency and model size for Vision-Language Models, enabling real-time, high-resolution processing without sacrificing accuracy.
Paper:
Related Papers:
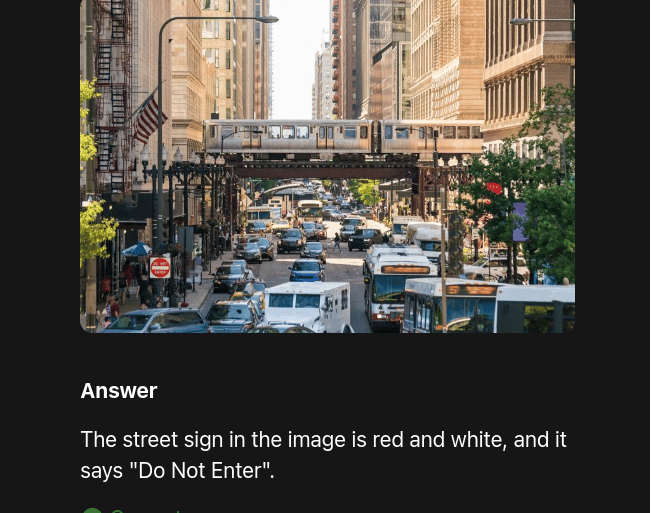
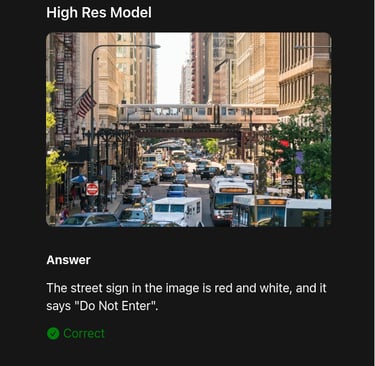
Overview
FastVLM introduces FastViTHD, a hybrid visual encoder that compresses high-resolution images into fewer tokens, greatly reducing encoding latency and encoder size. It enables Vision-Language Models to process high-res inputs quickly and efficiently—making on-device inference and real-time applications feasible.
Key Contributions
Hybrid FastViTHD Encoder: Optimizes visual token count, enabling fast, efficient high-res image processing.
Resolution-Scaling Simplicity: Achieves performance gains through smart scaling, without complex pruning or re-engineering.
High Speed and Compact Design: Offers up to 85× faster time-to-first-token and 3.4× smaller encoder compared to baseline VLMs, while maintaining accuracy.
Method (high-level)
FastVLM encodes high-resolution visuals by intelligently balancing token compression and data fidelity via the FastViTHD architecture. This enables Vision-Language Models to retain performance while drastically reducing computation for downstream tasks like captioning or image understanding.
Results
FastVLM matches or surpasses baseline benchmarks on tasks like SeedBench and MMMU—while delivering major speed and size improvements. Its efficiency opens doors for real-time video captioning and multimodal understanding applications, especially on edge devices.